
Live with Vinicius Moll at Rodrigo Branas Youtube channel!
Click on the Video to access the live: 👇👇👇👇👇
Schedule:
SRE - What does Site Reliability Engineering - SRE mean?
Agile vs DevOps vs SRE - Differences
Time SRE - What is involved in an SRE team?
SRE Principles
SLI / SLO / SLA
TOIL
Error Budget (Negotiated Error Budget)
Books on SRE
Site Reliability Engineering - SRE - Why so relevant?
Site Reliability Engineering - SRE, can be seen as an area that is willing to develop, establish and adhere to goals of availability and reliability of services provided by software applications.
Agile: Set of principles for software development lifecycle that promotes small, manageable changes quickly, ongoing collaboration, early delivery of working software, and continuous improvement in support of a business mission. Agile Manifesto
DevOps: Practice and culture shift driving Software Engineering (SE) and Production Management (PM) to collaborate together throughout the delivery lifecycle. Emphasis on shifting stability and security to the left with automation throughout the delivery pipeline. Ideally integrates with Agile practices to define feature success and prioritize the work with both teams present.
Site Reliability Engineering (SRE): Practice supported by skilled engineers, to establish and adhere to availability targets, service level objectives (SLOs), and error budgets set by end users. SREs have the ability to modify code to ensure adherence, and have basic telemetry capability to monitor where and when to modify applications. SRE implements DevOps practices.
DevOps Primary Focus = Delivery Speed
DevOps is a set of principles and practices that aims to break down IT silos and encourage collaboration, continuous delivery and delivery automation, Infrastructure as Code and joint (or even collapsed) responsibility for development and operate teams.
SRE Primary Focus = Reliability
SRE is a job function, where engineers are empowered to improve the reliability of a of a system by developing advanced telemetry, defining acceptable service levels and enforcing error budgets by accepting or rejecting code releases.
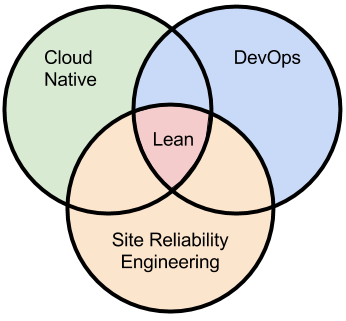
SRE DevOps - Venn Diagram view
DevOPS and SRE
=
Set of processes, practices, tools, standards, patterns, people, culture
SRE Mindset
You can be an SRE, DevOps, Developer, QA and Product Manager at the same time.
Don’t put yourself in a silo
Think about your customers, users, colleagues and communities around your service
The team should be able to understand their service end-to-end - Quality, cost, scope, security, compliance, etc …
YOU KNOW YOU’RE AN SRE WHEN…
- …you find yourself buying extras of everything because two is one and one is none.
- …you are involved in a new feature from design to deploy.
- …Production readiness reviews are something to look forward to.
- …you wonder what your power company’s SLO is.
Problems space
- The website is slow or down
- I get some errors while accessing the payment system
- I get a timeout when I try to upload a file greater than 10MB
- The app crashes on my phone
- The UI is so slow that I can’t interact with it
- All credit card information was leaked due to a security bug
- The app was down for a week due to a storm near one of our datacenters
Software Development Life Cycle
- It works on my laptop
- I don’t have access to troubleshoot the issue
- dev/test/prod environment are completely different
- If I apply a one-line change now, it takes 3h to build and 1h to deploy
- My release cycle is 3 months, but I need to react to the market at least bi-weekly
- I don’t know what was changed in since the last version
- I can’t roll back, too dangerous
- The app can’t support any more customers. They’ve reached the limit
- If I need to scale, I need to request more infrastructure and it takes 4 weeks to be ready
- The infrastructure for this application is costing us 1 million a month. We need to reduce to 800 thousand this year
- The documentation doesn’t represent the reality
- 1% of the traffic is responding with 500 HTTP Code
- I don’t have an environment with real data to reproduce the error
Solution space
Solution reside in having the following things with a proper strategy:
We need people
- That understands end-to-end and the technologies around to help fix issues
- That are available to support when needed
- That are transparent and learn from failures
- That are respectful when things go wrong
- That collaborate (if something is not working properly, it is a team’s problem)
- That put themselves in the customer/user shoes
- That understands why’s/what’s/how’s of their app, roadmap, cost, price, performance, tech stack, customer impact, customer satisfaction
- That are willing to learn and help outside their scope Oh, I am a developer and only know java, so if the app is down you should talk to ops people
Oh, I am an ops and there is a bug in the app. I’ve opened a ticket but the developers ignored me. They never test what they code.
- Collaboration, respect and customer mind-set
We need processes
- That facilitate automation
- That doesn’t require human intervention or reduce to a bare minimum
- That guarantees that if it passes in all stages, we are confident that it will not impact our customers
- That verifies our software is secure, reliable and work as expected
- That guarantee proper access to everyone involved
- That keep track of our failures and help us to improve
- That makes sure we are compliant with regulations
- That help us balance the priorities between functional and non-functional requirements
- That collect feedback and make sure our customers/users are happy
We need standards and patterns
- To facilitate collaboration and communication
- To help us design and implement better systems
- To become compliant
- To help us address complex designs
- distributed systems
- microservices
- scalability
- resiliency
- 12-factor
And we need a culture:
- Which support the team under heavy load and tough times
- Which encourages transparency and a blameless culture
- Which encourages collaboration between teams
- Which encourages failures as a step to improve and learn
- That embraces agility and fast feedback interactions
SRE Principles
- Embracing risk
- Service Level Objectives (SLO)
- Eliminate repetitive or unnecessary work
- Monitor distributed systems
- Automation
- Launch engineering
- Simplicity
SLI / SLO / SLA
Next we have the definition of each of this concepts.
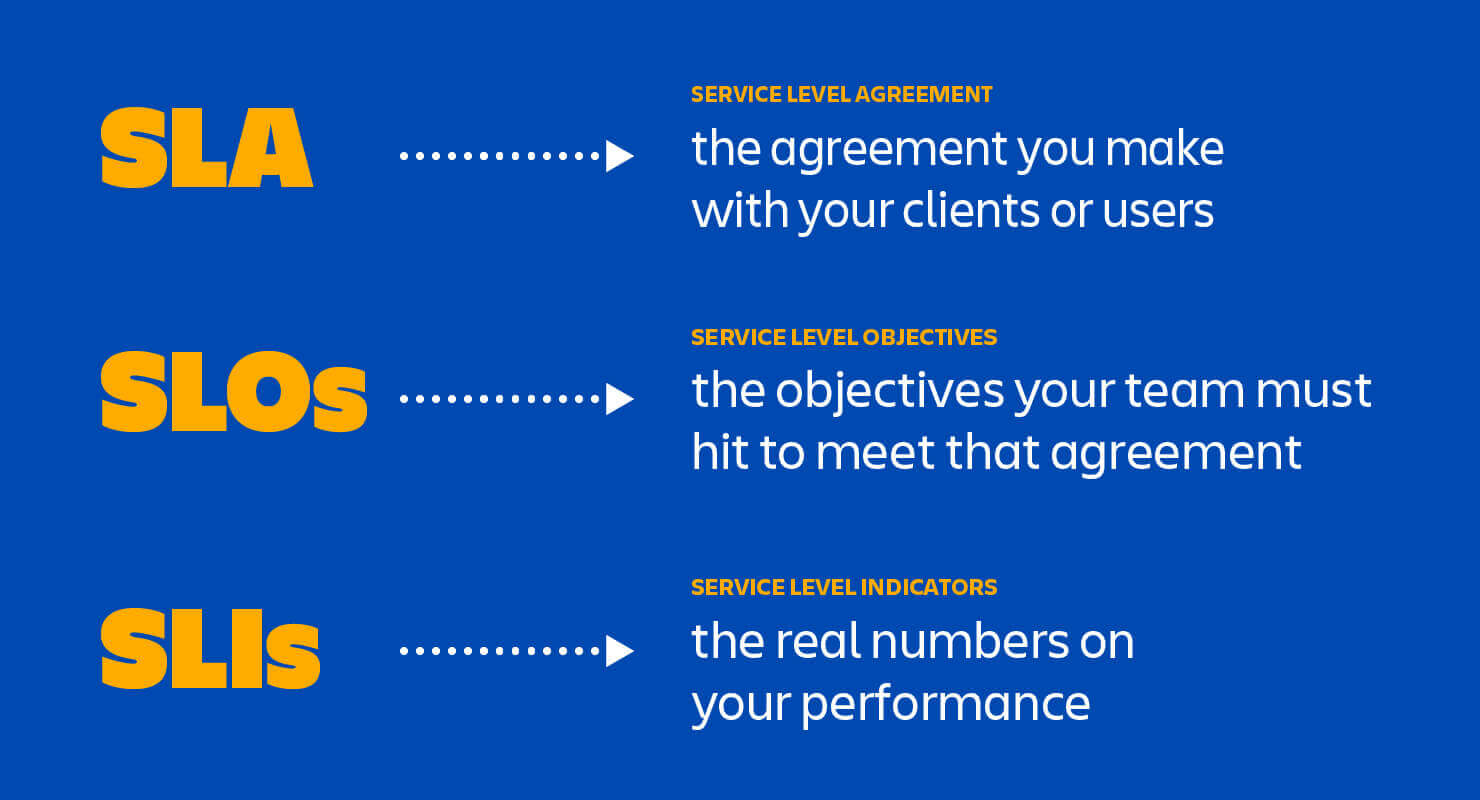
Overview - SLA vs SLI vs SLO
Service Level Indicator
A carefully defined quantitative measure of some aspect of the level of service that is provided. As an example, we can think in terms of the VALET (Volume, Availability, Latency, Errors e Tickets) dashboard proposed by Google.
Service Level Objective
A target value or range of values for a service level that is measured by an SLI. A natural structure for SLOs is thus SLI ≤ target, or lower bound ≤ SLI ≤ upper bound
Service Level Aggrement
The SLA is the entire agreement that specifies what service is to be provided, how it is supported, times, locations, costs, performance, and responsibilities of the parties involved
TOIL
It is not just “work I don’t like to do”
Overhead is often work not directly tied to running a production service, and includes tasks like team meetings, setting and grading goals, snippets, and HR paperwork
Candidates for Toil
- Manual work
- Automatable
- Tactical (interrupt-driven and reactive)
- No enduring value
- O(n) with service growth
Error Budget
This topic was very well defined in this other article, according to the good practices established between the SRE teams on google. Source: https://blog.estabil.is/sre-error-budget/
To define this Error Budget metric, the Product and SRE teams come together to jointly define a quarterly error budget based on the service level objective (SLO). This error budget is a clear and objective metric that determines how long within those 3 months the service may be unavailable (or unreliable).
This metric, previously defined and taken together, eliminates the stress of politics and negotiations between development and operations teams to define the level of risk that should be assumed in an update of the service.
The usual way of calculating service availability is by observing its uptime and unplanned downtime:
availability = uptime / (uptime + downtime)
However, in the SRE book, Google suggests to use a different metric and define availability in terms of request success rate:
availability: availability = successful requests / total requests
Table for calculation of 99’s of availability percentage, see here the table.
How does Google work with error budgeting?
In the case of google, the product management team defines the SLO for the service, which is how much availability the service can have in the quarter.
The monitoring system is responsible for measuring this availability faithfully and impartially.
The difference between the established SLO and the actual availability of the service is the error budget that remains to be spent in the quarter.
As long as the service availability time, which is measured by the monitoring tool, is longer than the SLO, then it is possible to continue making updates to the production environment.
Practical example - Error budget
For example, let’s say that the Gmail service has an SLO that allows an unavailability of up to 4 hours in the quarter. If, after 1 month, there were only 2 hours of unavailability, then the product team, together with the SRE team, can continue to apply service updates as long as it does not exceed 4 hours within the quarter. However, if in the first month there were more than 4 hours of unavailability, then the service will be in freeze until the end of the quarter, and cannot undergo changes that put its reliability at risk.
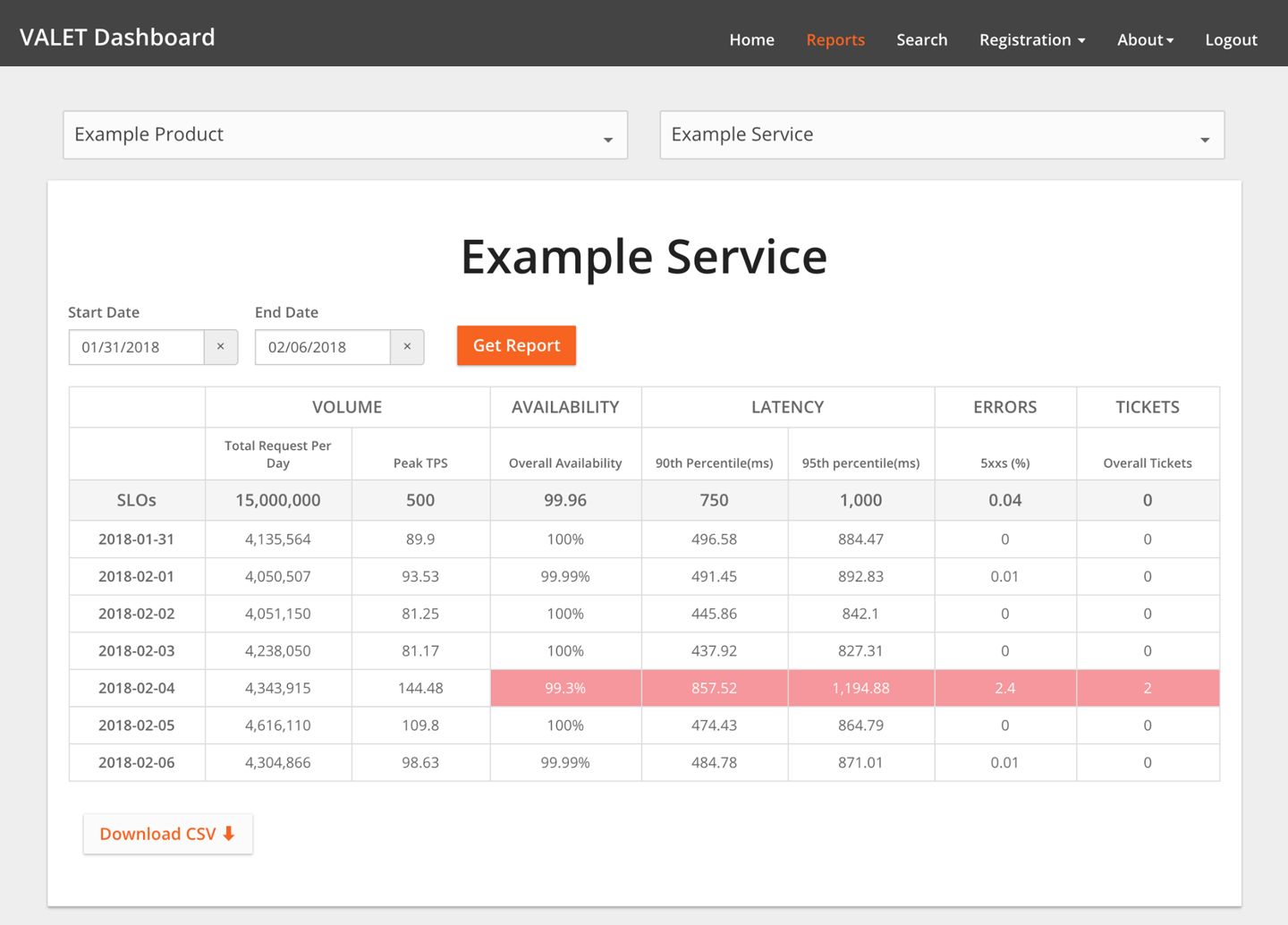
SRE VALET Dashboard - SLO
A Atlassian has a simple sample about calculation of error budget by the 99.XX’s that we expect here.
| SLA target | Yearly allowed downtime | Monthly allowed downtime |
|---|---|---|
| 99.99% uptime | 52 minutes, 35 seconds | 4 minutes, 23 seconds |
| 99.95% uptime | 4 hours, 22 minutes, 48 seconds | 21 minutes, 54 seconds |
| 99.9% uptime | 8 hours, 45 minutes, 57 seconds | 43 minutes, 50 seconds |
| 99.5% uptime | 43 hours, 49 minutes, 45 seconds | 3 hours, 39 minutes |
| 99% uptime | 87 hours, 39 minutes | 7 hours, 18 minutes |
We also have the possibility to see an example of applying a service’s SLO, to validate whether we should generate any type of alert when the values are below or above what was agreed for the SLO.
Another sample using Prometheus e Grafana is here
What are the benefits of applying the Error budget concept?
The main benefit is the alignment of objectives between product times and SRE, to find the right balance between innovation and efficiency.
This balance can be seen when, for example, product development time chooses to reduce the time spent on testing to increase the speed of delivery of new code in production. As long as the error budget is high, they can choose to take more risks and accelerate innovation. However, when the budget is already low, close to bursting, developers will continue to be more cautious, policing themselves to do more tests and send updates to production less often.
Both the product time and the SRE time are responsible for the error budget, therefore, an occasional failure due to infrastructure problems impacting this indicator and affecting the delivery schedule for the entire quarter.
Additional sources: https://www.atlassian.com/br/incident-management/kpis/error-budget and https://neoteric.eu/blog/what-is-an-error-budget/
Another sample of implementation of SLO’s is here
Just to highlight the Postmortem process, see next picture:
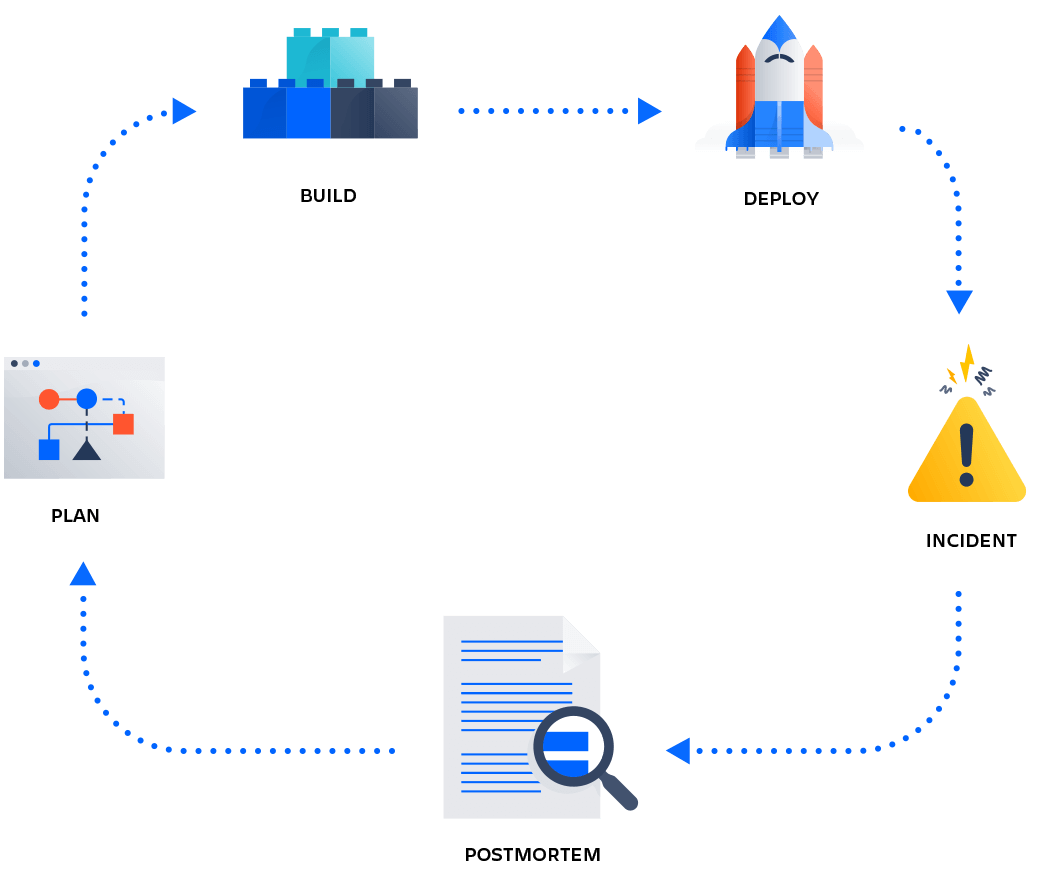
Postmortem/blameless SRE process
SRE Mindset
You built it, you run it - https://www.atlassian.com/br/incident-management/devops/sre
You can be an SRE, DevOps, Developer, QA and Product Manager at the same time. Don’t put yourself in a silo. Think about your customers, users, colleagues and communities around your service. The team should be able to understand their service end-to-end - Quality, cost, scope, security, compliance, etc …
YOU KNOW YOU’RE AN SRE WHEN…
- …you find yourself buying extras of everything because two is one and one is none.
- …you are involved in a new feature from design to deploy.
- …Production readiness reviews are something to look forward to.
- …you wonder what your power company’s SLO is.
https://learning.oreilly.com/library/view/seeking-sre/9781491978856/part03.html
SRE Book Tips
In this final section, I want to take the opportunity to recommend five books, among them one that I strongly recommend reading and acquisition because it also addresses aspects of the career in SRE is: Real World SRE.
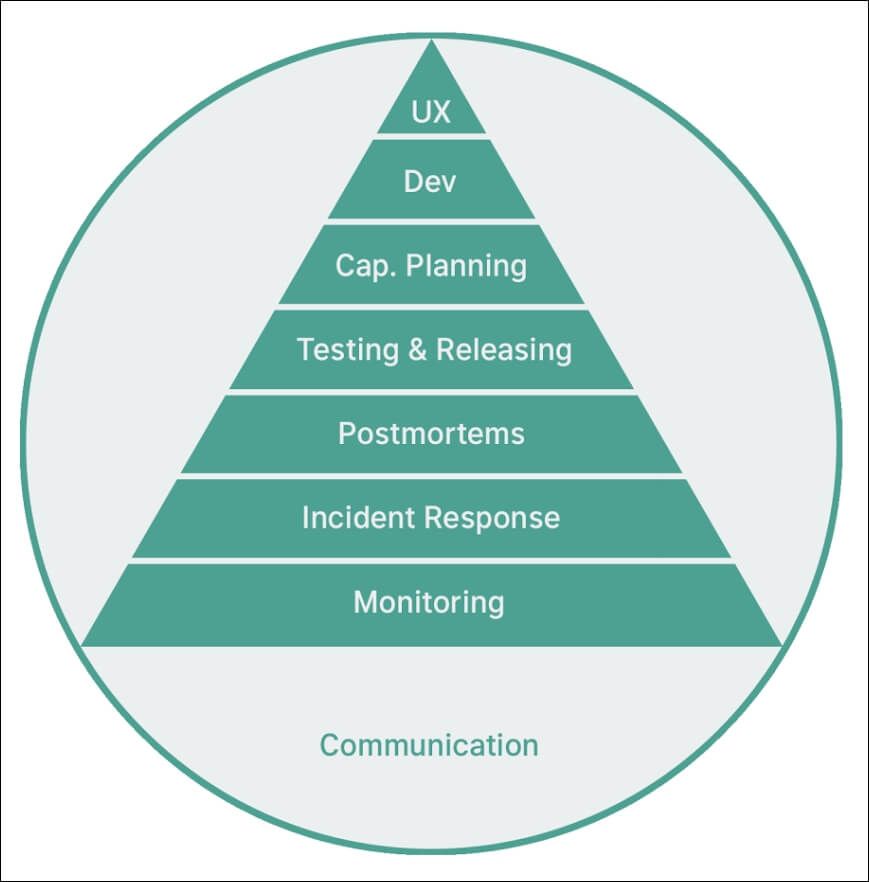
SRE Layers
This area has many branches and many of them can help you in your current position, improving the way you act as Customer success, Product Owner, Developer, Tester, Support, Infrastructure and many other related areas.
The second book is Seeking SRE, which provides several examples of how to manage incidents and can help improve the processes of your development and delivery team.
The other two books are from Google, the first of which is more theoretical (Site Reliability Engineering - How Google runs production systems) and the other more applied practice, aimed at implementing SRE (The Site Reliability Workbook - How to Implement SRE Practices).
The most recent book (made available for free 😜) by Building Secure & Reliable Systems 😎.
One last thing that can be very helpful: Road map DevOps/SRE
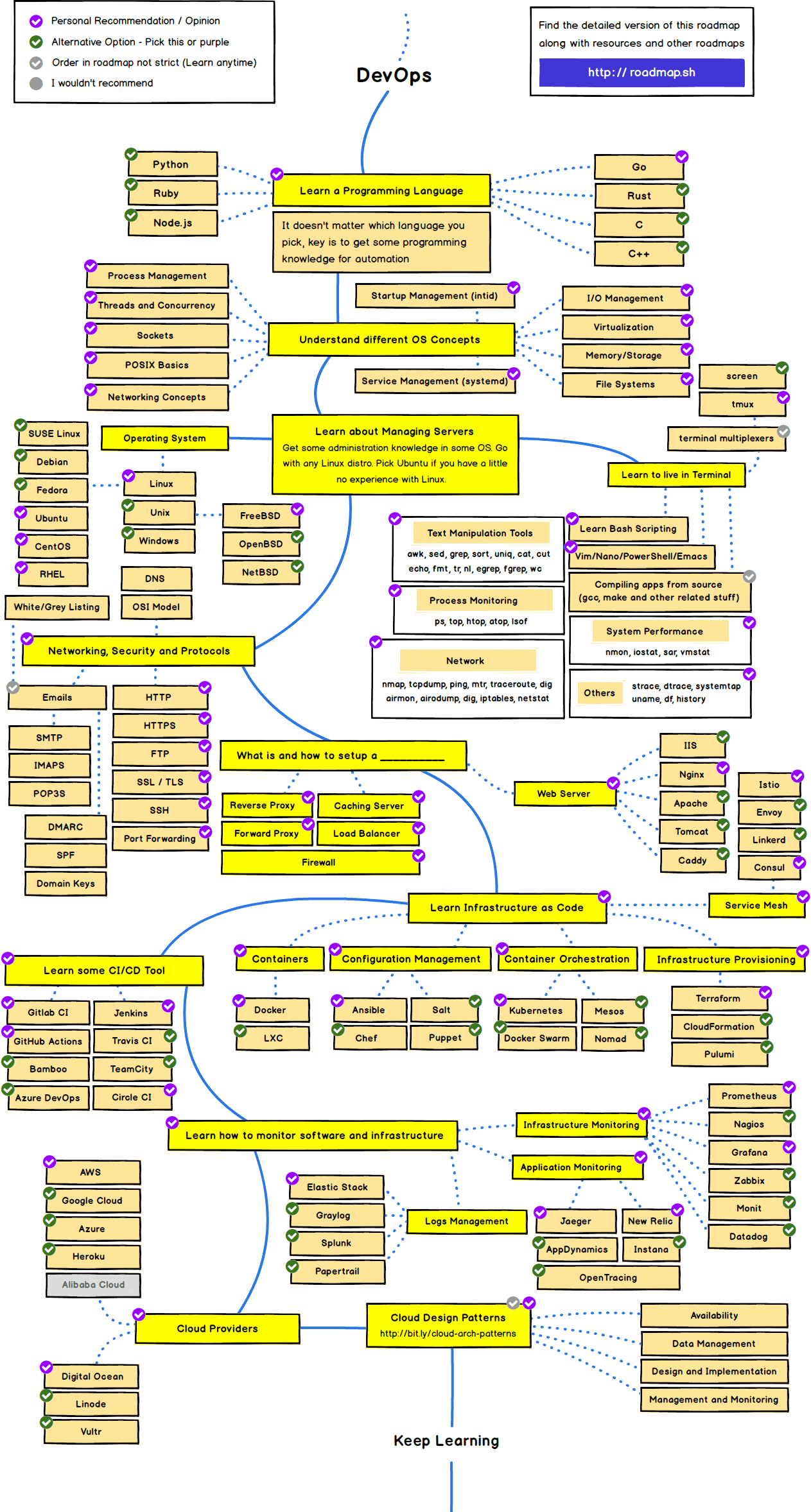
DevOps | SRE - Roadmap
I hope you enjoyed the topics covered in this article and the tips from books.
Leave your comment, follow my new profile on twitter and instagram @sretips, subscribe to my Youtube channel and stay tuned, because every week we will have videos and new topics that may be of interest to you. Big hug and see you next time! 😉👍
References
- https://www.atlassian.com/br/incident-management/kpis/error-budget https://neoteric.eu/blog/what-is-an-error-budget/
- https://blog.estabil.is/o-que-e-sre-site-reliability-engineering/
- https://landing.google.com/sre/interview/ben-treynor-sloss/
- https://landing.google.com/sre/books/
- https://learning.oreilly.com/library/view/real-world-sre
- https://learning.oreilly.com/library/view/seeking-sre/9781491978856/part03.html
- https://learning.oreilly.com/library/view/site-reliability-engineering/9781491929117/ch01.html
- https://opensource.com/article/18/10/what-site-reliability-engineer
- https://dwpdigital.blog.gov.uk/category/site-reliability-engineering-sre/
- https://keetmalin.wixsite.com/keetmalin/post/what-is-site-reliability-engineering-sre
- https://cloudposse.com/demo/site-reliability-engineering/
- https://www.xenonstack.com/insights/site-reliability-engineer/
- https://blogs.vmware.com/services-education-insights/files/2018/11/SRE-Paper.pdf
Please, follow our social networks:
Thank You and until the next one! 😉👍
Published on Jun 09, 2020 by Vinicius Moll