
Assista a Live em 14-06-2020 19 horas (Brasil) sobre SRE com Vinicius Moll e Rodrigo Branas aqui no canal do Youtube!
Clique no video para acessar a Live 👇👇👇👇👇
Agenda:
SRE - O que significa Site Reliability Engineering – SRE?
Agile vs DevOps vs SRE - Diferenças
Time SRE - O que está envolvido em um time de SRE?
Principios SRE
SLI / SLO / SLA
TOIL
Error Budget (Orçamento de Erros negociado)
Livros sobre SRE
SRE - O que significa Site Reliability Engineering – SRE?
Antes de irmos direto ao assunto, é muito importante definirmos o termo SRE - O que significa Site Reliability Engineering – SRE?
A Engenharia de Confiabilidade, do ingles (Site Reliability Engineering - SRE), pode ser vista como uma area que se dispõe a desenvolver, estabelecer e aderir a metas de disponibilidade e confiabilidade dos serviços fornecidos pelas aplicações de software.
Agile vs DevOps vs SRE - Diferenças
Ágil: conjunto de princípios para o ciclo de vida de desenvolvimento de software que promove mudanças pequenas e gerenciáveis rapidamente, colaboração contínua, entrega antecipada de software em funcionamento e aprimoramento contínuo no suporte a uma missão comercial. Manifesto Ágil
DevOps: mudança de prática e cultura, levando a Engenharia de Software (SE) e o Gerenciamento de Produção (PM) a colaborarem juntos durante todo o ciclo de vida da entrega. Ênfase na mudança de estabilidade e segurança para a esquerda com automação em todo o pipeline de entrega. Idealmente, integra-se às práticas ágeis para definir o sucesso dos recursos e priorizar o trabalho com as duas equipes presentes.
Engenharia de confiabilidade do site (Site reliability Engineering - SRE): prática suportada por engenheiros qualificados, para estabelecer e aderir a metas de disponibilidade, objetivos de nível de serviço (SLOs) e orçamentos de erros definidos pelos usuários finais. Os SREs podem modificar o código para garantir a aderência e possuem recursos básicos de telemetria para monitorar onde e quando modificar aplicativos. SRE implementa as praticas do DevOps.
Foco principal do DevOps = velocidade de entrega
O DevOps é um conjunto de princípios e práticas que visa desmembrar os silos de TI e incentivar a colaboração, a entrega contínua e a automação de entrega, Infraestrutura como código e responsabilidade conjunta (ou mesmo colapsada) pelo desenvolvimento e operação de equipes.
Foco Primário do SRE = Confiabilidade
O SRE é uma função do trabalho, na qual os engenheiros têm o poder de melhorar a confiabilidade de um sistema, desenvolvendo telemetria avançada, definindo níveis de serviço aceitáveis e aplicando orçamentos de erro ao aceitar ou rejeitar liberações de código.
DevOPS e SRE
Conjunto de processos, práticas, ferramentas, regulamentos, padrões, pessoas, cultura e mais importante aplicação de tudo isso na prática (famoso mão 🖐 🤚 na massa).
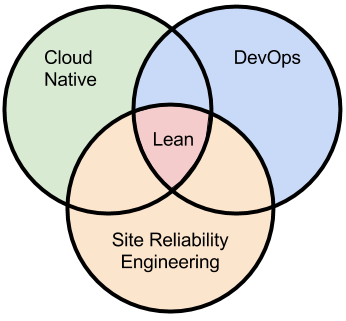
SRE DevOps - Diagrama de Venn
Time SRE - O que está envolvido em um time de SRE?
- Conjunto de processos, praticas, ferramentas, padrões, compliances, pessoas, cultura
Principios SRE
- Abraçar o risco
- Objetivos do Nível de Serviço (SLO)
- Eliminar o trabalho repetitivo ou desnecessário
- Monitorar sistemas distribuídos
- Automação
- Engenharia de lançamento
- Simplicidade
SLI / SLO / SLA
A figura a seguir mostra a definição de cada elemento.
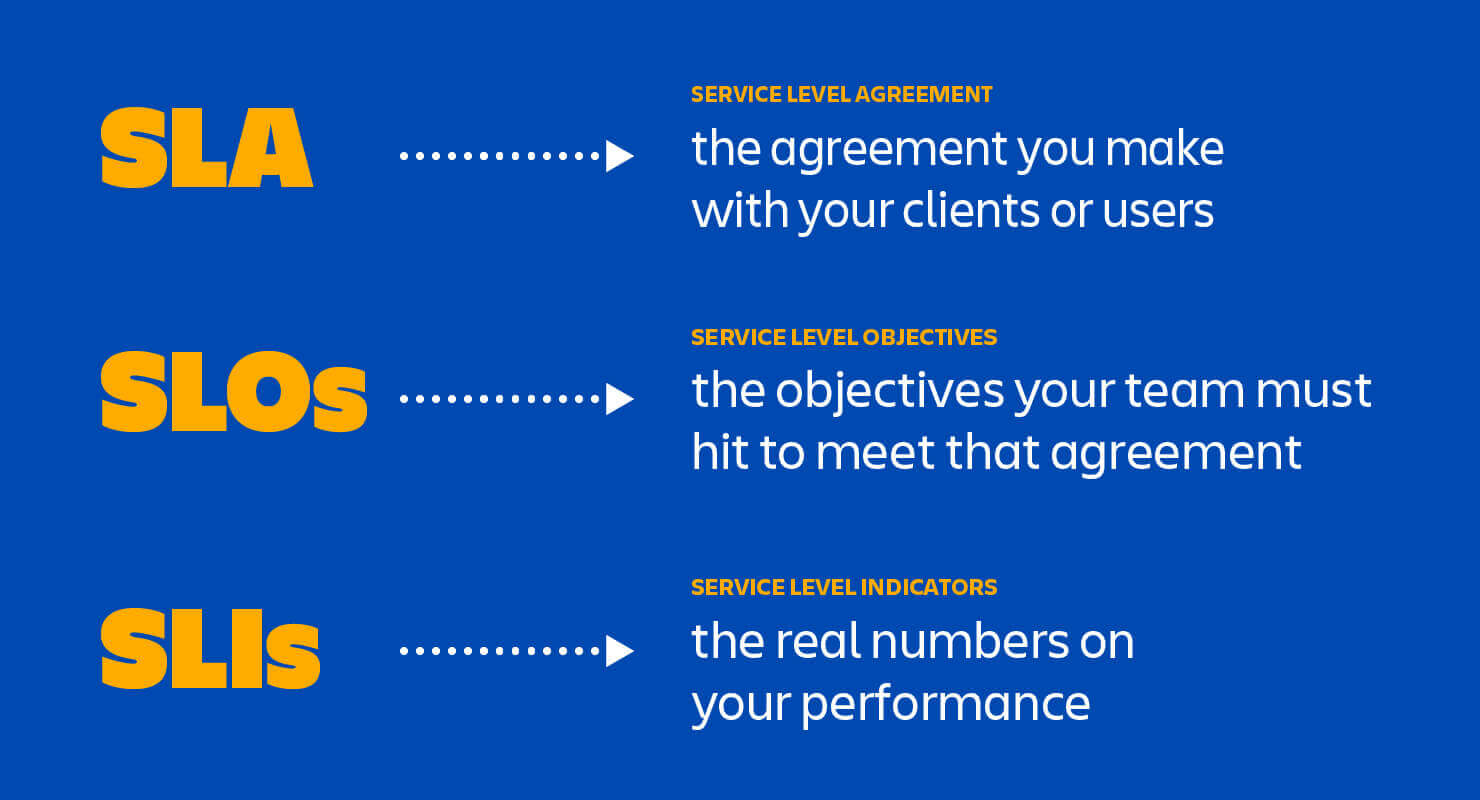
Visao geral - SLA vs SLI vs SLO
SLI - Indicador de Nível de Serviço
Uma medida quantitativa cuidadosamente definida de algum aspecto do nível de serviço fornecido.
Por exemplo, podemos pensar nos itens do VALET (Volume, Availability, Latency, Errors e Tickets) do dashboard proposto pelo Google.
SLO - Objetivo do nível de serviço
Um valor alvo ou intervalo de valores para um nível de serviço medido por uma SLI. Uma estrutura natural para SLOs é, portanto, SLI ≤ alvo ou limite inferior ≤ SLI ≤ limite superior
SLA - Aumento do nível de serviço
O SLA é todo o contrato que especifica qual serviço deve ser fornecido, como é suportado, horários, locais, custos, desempenho e responsabilidades das partes envolvidas
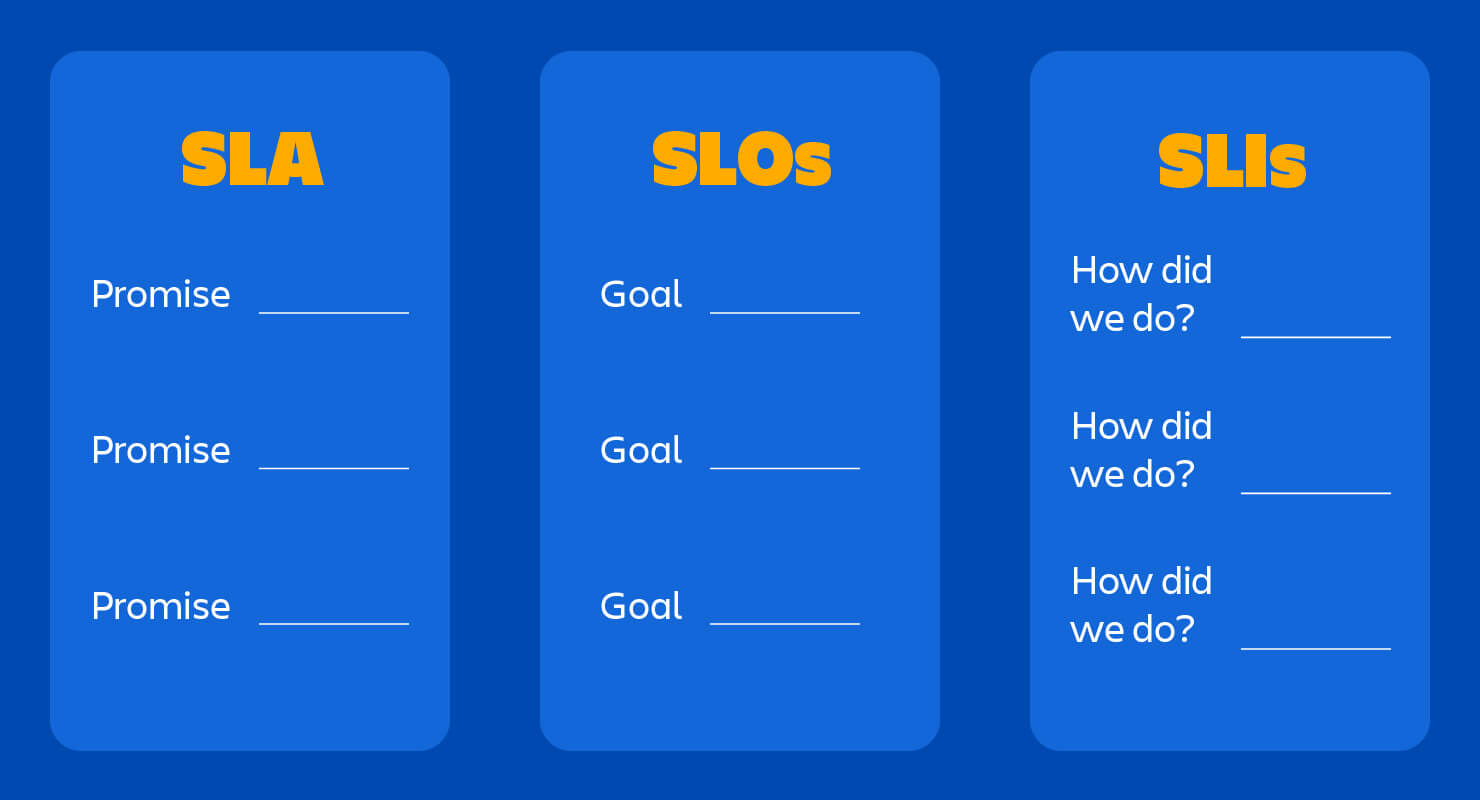
Exemplos - SLA vs SLI vs SLO
Fonte e exemplos de SLI vs SLO vs SLA
TOIL - Por que voce deve se importar em reduzí-lo?
Toil refere-se a todo trabalho manual que pode e deve ser automatizado, overhead para o time, para as entregas e para o planejamento.
Não é apenas “trabalho que não gosto de fazer”
Geralmente, as despesas gerais não estão diretamente ligadas à execução de um serviço de produção e incluem tarefas como reuniões de equipe, estabelecimento de metas e classificação, trechos e documentação de RH
Candidatos a Toil:
- trabalho manual que pode ser automatizado
- Tático (acionado por interrupção e reativo)
- Nenhum valor duradouro
- O(n) com crescimento do serviço
Error Budget (Orçamento de Erros negociado)
Esse tópico foi muito bem definido neste outro artigo, segundo as boas práticas estabelecidas entre os times de SRE no google. Fonte: https://blog.estabil.is/sre-error-budget/
Para definir esta métrica de Error Budget, times de Produtos e SRE se reunem para definir em conjunto um orçamento de erro trimestral com base no objetivo de nível de serviço (SLO). Este orçamento de erro é uma métrica clara e objetiva que determina quanto tempo dentro desses 3 meses o serviço poderá ficar indisponível (ou não-confiável).
Essa métrica, definida previamente e em conjunto acaba com o stress da politicagem e de negociações entre times de desenvolvimento e operações para definir qual o nível de risco que se deve assumir em uma atualização do serviço.
A maneira usual de calcular a disponibilidade do serviço é observando o tempo de atividade e o tempo de inatividade não planejado:
disponibilidade = tempo de atividade / (tempo de atividade + tempo de inatividade)
No entanto, no livro do SRE, o Google sugere usar uma métrica diferente e definir a disponibilidade em termos da taxa de êxito da solicitação:
disponibilidade = solicitações bem-sucedidas / total de solicitações
Tabela de calculo de porcentagem de disponibilidade, veja aqui um exemplo.
Como o Google trabalha com orçamento de erro?
No caso do google, o time de gerenciamento do produto define o SLO para o serviço, que é quanto tempo de de disponibilidade o serviço pode ter no trimestre.
O sistema de monitoramento é responsável por medir de forma fiel e imparcial essa disponibilidade.
A diferença entre o SLO estabelecido e a disponibilidade real do serviço é o orçamento de erro que ainda falta ser gasto no trimestre.
Enquanto o tempo de disponibilidade do serviço, que é medido pela ferramenta de monitoramento, estiver maior que o SLO, então é possível continuar fazendo atualizações no ambiente em produção.
Exemplo prático - Error budget
Para exemplificar, digamos que o serviço Gmail tenha um SLO que permita uma indisponibilidade de até 4 horas no trimestre. Se, após 1 mês houve apenas 2 horas de indisponibilidade, então o time de produtos, juntamente com o time de SRE ainda pode continuar aplicando atualizações no serviço desde que não extrapole as 4 horas dentro do trimestre. Porém, se logo no primeiro mês houve mais do que 4 horas de indisponibilidade, então o serviço entrará em freeze até o final do trimestre, não podendo sofrer alterações que coloquem em risco sua confiabilidade.
Temos ainda a possibilidade de ver um exemplo (na figura a seguir) de aplicação do SLO de um serviço, para validar se devemos gerar algum tipo de alerta ou sinalização quando os valores ficam abaixo ou acima do acordado para o SLO.
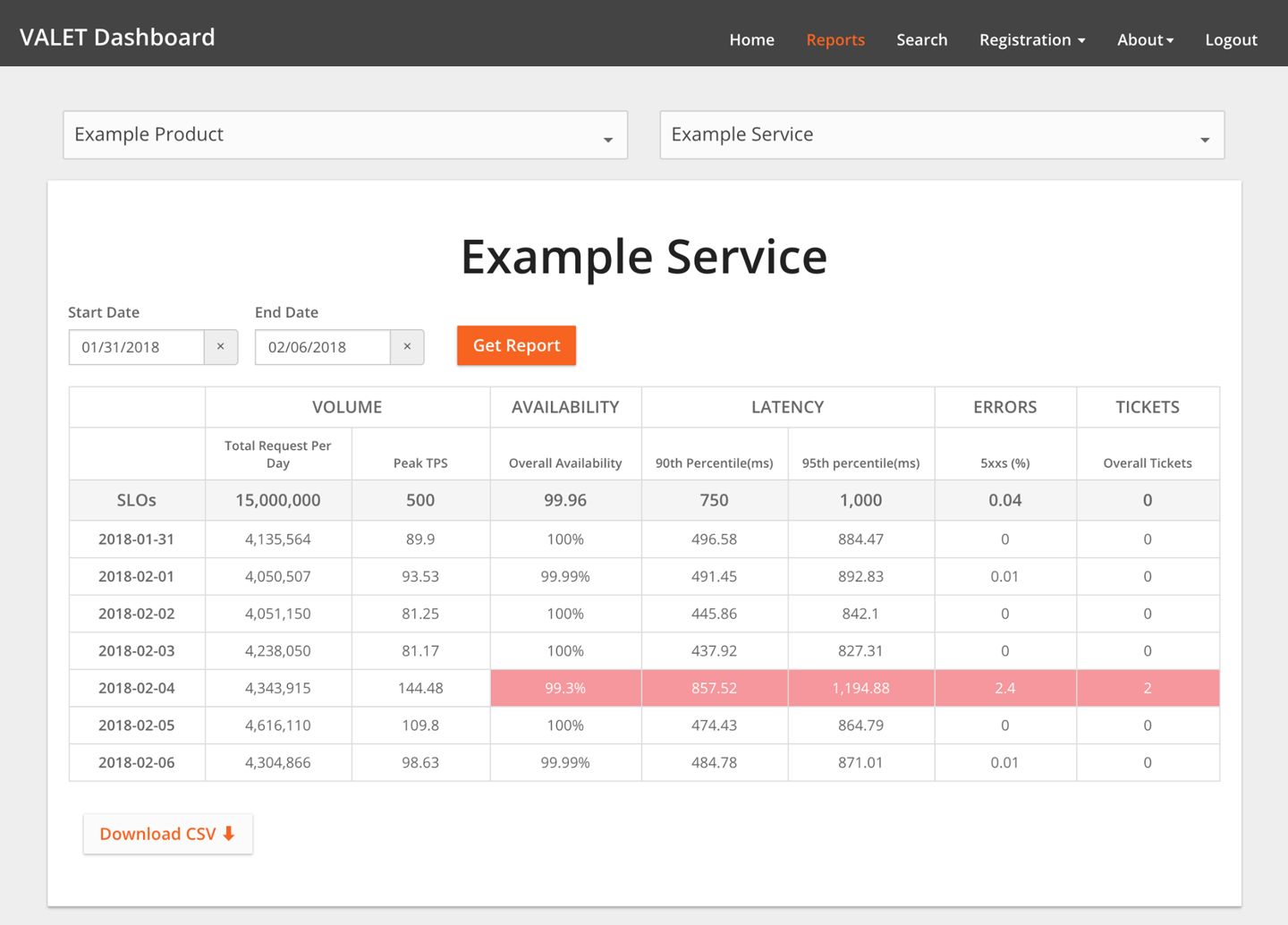
SRE VALET Dashboard - SLO
Fonte: https://landing.google.com/sre/workbook/chapters/slo-engineering-case-studies/#the-valet-dashboard
A Atlassian tem um exemplo bem simples de como calcular o error budget de acordo com o nivel de 99.XX’s que queremos neste artigo.
| SLA target | Yearly allowed downtime | Monthly allowed downtime |
|---|---|---|
| 99.99% uptime | 52 minutes, 35 seconds | 4 minutes, 23 seconds |
| 99.95% uptime | 4 hours, 22 minutes, 48 seconds | 21 minutes, 54 seconds |
| 99.9% uptime | 8 hours, 45 minutes, 57 seconds | 43 minutes, 50 seconds |
| 99.5% uptime | 43 hours, 49 minutes, 45 seconds | 3 hours, 39 minutes |
| 99% uptime | 87 hours, 39 minutes | 7 hours, 18 minutes |
Outro exemplo usando Prometheus e Grafana pode ser visto aqui
Quais os benefícios ao aplicar o conceito de Error budget?
O principal benefício é o alinhamento de objetivos entre os times de produtos e de SRE, para que encontrem o equilíbrio adequado entre inovação e confiabilidade.
Este equilíbrio pode ser visto quando, por exemplo, o time de desenvolvimento de produtos opta por reduzir o tempo gasto na etapa de testes para aumentar a velocidade de entrega de código novo em produção. Enquanto o orçamento de erro está alto, então eles podem optar por se arriscarem mais e acelerar a inovação. Porém, quando o orçamento já está baixo, próximo a estourar, os próprios desenvolvedores serão bem mais cautelosos, se policiando para fazerem mais testes e mandar atualizações para produção com menor frequência.
Tanto o time de produtos quanto o time de SRE são responsáveis pelo orçamento de erro, portanto uma falha ocasionada por problemas na infraestrutura impactará neste indicador e afetará o roadmap de entregas de todo o trimestre.
Fontes adicionais: https://www.atlassian.com/br/incident-management/kpis/error-budget e https://neoteric.eu/blog/what-is-an-error-budget/
Problemas vs Soluções
Nesta seção, vamos abordar alguns dos principais problemas que a área de SRE aborda e as principais soluções relacionadas.
Problemas do ponto de vista dos clientes / usuários 🤬😡😤🥺🤯🥵
- Serviço oferecido não está orientado para o cliente / usuários na ponta
- O site está lento ou inativo
- Eu recebo alguns erros ao acessar o sistema de pagamento
- Recebo um tempo limite ao tentar fazer upload de um arquivo com mais de 10 MB
- O aplicativo trava no meu telefone
- A interface do usuário é tão lenta que não consigo interagir com ela
- Todas as informações do cartão de crédito vazaram devido a um erro de segurança
- O aplicativo ficou inativo por uma semana devido a uma tempestade perto de um de nossos datacenters
Problemas no contexto do Ciclo de vida do desenvolvimento de software - SDLC
- Funciona no meu laptop
- Não tenho acesso para solucionar o problema
- O ambiente dev / test / prod é completamente diferente
- Se eu aplicar uma alteração de uma linha agora, leva 3h para construir e 1h para implantar
- Meu ciclo de lançamento é de 3 meses, mas preciso reagir ao mercado pelo menos duas vezes por semana
- Não sei o que foi alterado desde a última versão
- Eu não posso reverter, muito perigoso
- O aplicativo não pode suportar mais clientes. Eles atingiram o limite
- Se precisar escalar, preciso solicitar mais infraestrutura e leva 4 semanas para estar pronto
- A infraestrutura para esse aplicativo está nos custando 1 milhão por mês. Precisamos reduzir para 800 mil este ano
- A documentação não representa a realidade
- 1% do tráfego está respondendo com o código HTTP 500
- Não tenho um ambiente com dados reais para reproduzir o erro
Soluções
Precisamos de pessoas qualificadas e com boa disposição para:
- Promover mudanças (culturais, processos, metodologias de gestão)
- Compreender de ponta a ponta e as tecnologias disponíveis para ajudar a corrigir problemas
- Estão disponíveis para suporte quando necessário
- Que são transparentes e aprendem com falhas
- Que sejam respeitosas quando as coisas dão errado (e elas as vezes dão errado no começo, e de que lado você pretende estar, vai fazer toda a diferença se você for parte do problema ou da solução)
- Que colaboram (se algo não está funcionando corretamente, é um problema da equipe)
- Que se colocam no lugar do cliente / usuário
- Que entende por que / o que é / como é a aplicação / processo do cliente / todo ciclo de oferta do serviço.
- Capaz de compreender o: roteiro, custo, preço, desempenho, pilha tecnológica, impacto no cliente, satisfação do cliente
- Que estejam dispostas a aprender e ajudar fora do seu escopo
Ah, eu sou desenvolvedor e só conheço java, por isso, se o aplicativo estiver inativo, você deve conversar com as pessoas das operações…
Ah, eu sou um ops e há um bug no aplicativo. Abri um ticket, mas os desenvolvedores me ignoraram. Eles nunca testam o que codificam…
- Colaboração, respeito e mentalidade do cliente
Precisamos de processos
Processos –> Automação –> Melhorias dos serviços, confiabilidade, disponibilidade, …
- Isso facilita a automação
- Isso não requer intervenção humana ou reduz ao mínimo
- Isso garante que, se for aprovado em todas as etapas, estamos confiantes de que isso não afetará nossos clientes.
- Isso verifica se nosso software é seguro, confiável e funciona como esperado
- Que garantem acesso adequado a todos os envolvidos
- Que acompanham nossas falhas e nos ajudam a melhorar
- Isso garante que estamos em conformidade com os regulamentações de nossa área de trabalho
- Isso nos ajuda a equilibrar as prioridades entre requisitos funcionais e não funcionais
- Que coletam feedback e garantem que nossos clientes / usuários estejam felizes
- Precisamos de padrões
- Para facilitar a colaboração e comunicação
- Para nos ajudar a projetar e implementar melhores sistemas
- Para se tornar compatível
- Para nos ajudar a lidar com projetos complexos
- Para auxiliar e guiar o projeto de Sistemas distribuídos
- Validar uso e necessidade de microserviços
- escalabilidade
- resiliência
- Seguir os Doze Fatores
E precisamos de uma cultura
- Que apoia a equipe sob carga pesada de trabalho e tempos difíceis
- O que incentiva a transparência e uma cultura irrepreensível
- Que incentiva a colaboração entre equipes
- Que incentiva as falhas como um passo para melhorar e aprender
- Que abraça agilidade e interações rápidas de feedback
- Cultura Blameless/Postmortem
- Engenharia de lançamento ou Launch Coordination Engineering (LCE)
- Comunicação e colaboração
- Gerenciamento do risco
- E não menos importante, que seja capaz de fortalecer uma nova mentalidade entre cada indivíduo.
Apenas para enfatizar a importancia do Postmortem, note a figura a seguir:
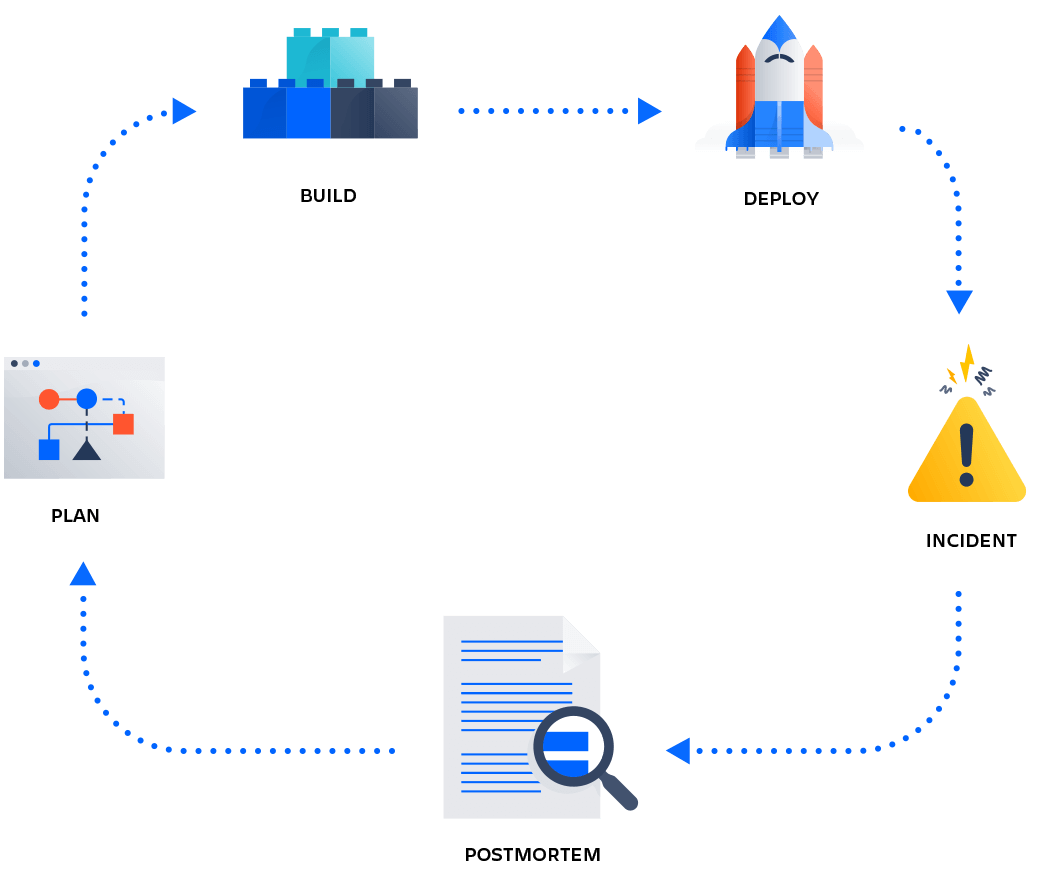
Processo de Postmortem/blameless SRE
Gerenciamento de Incidentes
Todo incidente possui um ciclo de vida. De maneira resumida, podemos pensar nesse ciclo de vida em termos de pontos no tempo que precisam ser registrados, para auxiliar desde a detecção ate o momento em que os incidentes sao resolvidos.
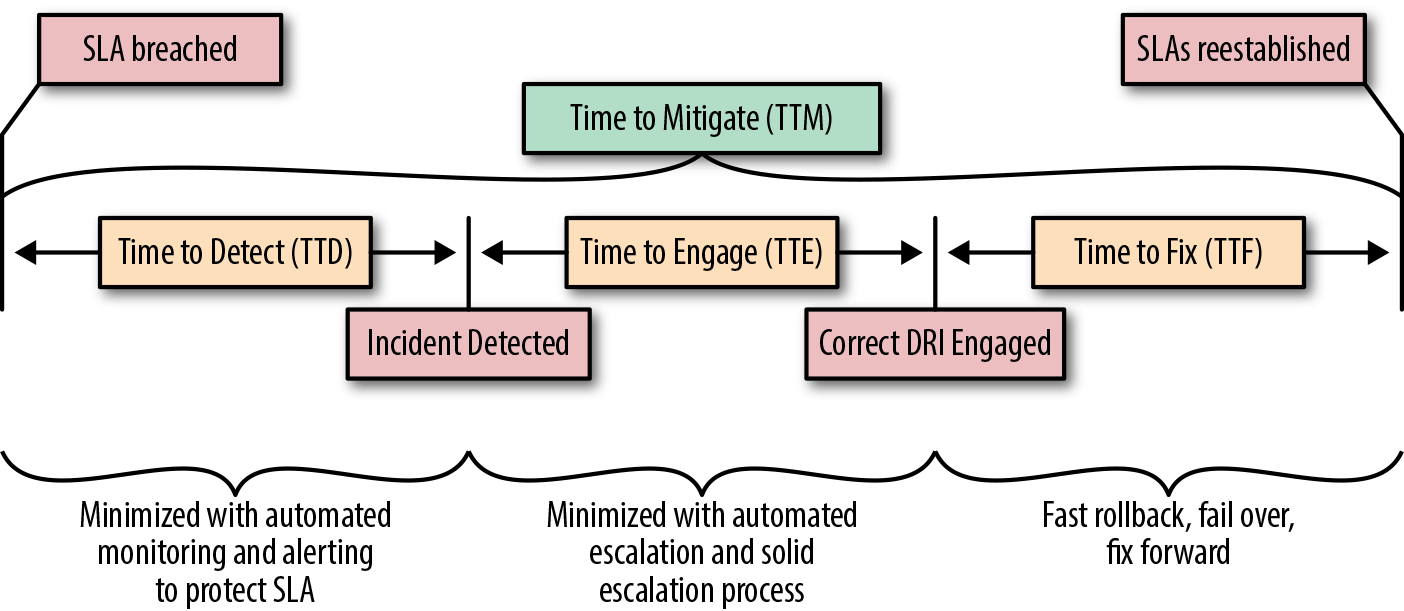
Ciclo de Vida e gerenciamento de Incidentes - SRE
Importante realizar medições para nao permanecer em um ciclo vicioso de detecção de bugs até a correção e release de nova versão.
SRE Mindset
You built it, you run it
https://www.atlassian.com/br/incident-management/devops/sre
Você pode ser um SRE, DevOps, Desenvolvedor, QA e Gerente de Produto ao mesmo tempo.
Não se coloque em um silo.
Pense nos seus clientes, usuários, colegas e comunidades em torno do seu serviço.
A equipe deve entender o serviço de ponta a ponta - qualidade, custo, escopo, segurança, conformidade, etc.
Você sabe que é um SRE quando …
- … você se vê comprando extras de tudo, porque dois são um e um é nenhum.
- … você está envolvido em um novo recurso, do design à implantação.
- … As análises de prontidão de produção são algo a se esperar.
- … você se pergunta qual é o SLO da sua empresa de energia.
Dicas de Livros sobre SRE
Nesta seção final, quero aproveitar para recomendar cinco livros, entre eles um que recomendo fortemente a leitura e aquisição por que também aborda aspectos da carreira em SRE é o: Real World SRE
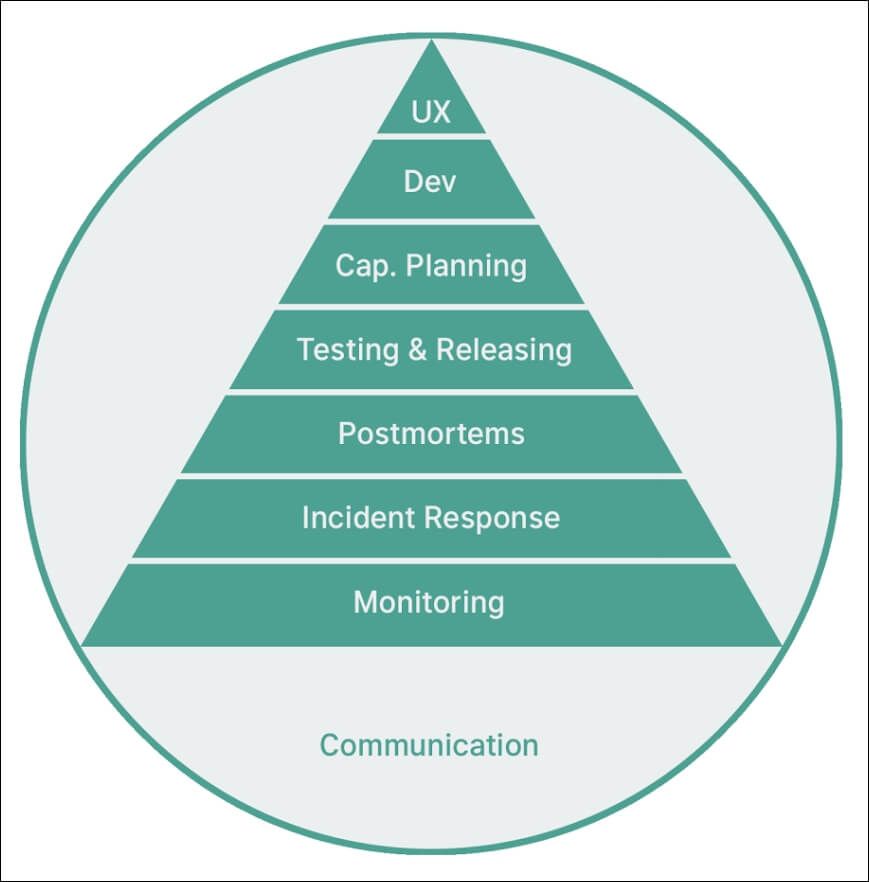
SRE Camadas
Esta área possui muitas ramificações e muitas delas podem ajudar você no seu cargo atual, melhorando a forma como você atua como Customer success, Product Owner, Desenvolvedor, Tester, Suporte, Infraestrutura e tantas outras areas relacionadas.
Segundo livro é o Seeking SRE, que traz diversos exemplos de como gerenciar incidentes e pode auxiliar na melhoria de processos de seu time de desenvolvimento e entregas.
Os outros dois livros são do Google, o primeiro deles mais teórico (Site Reliability Engineering - How Google runs production systems) e o outro mais prática aplicada, voltada a implementação de SRE (The Site Reliability Workbook - How to Implement SRE Practices).
O mais recente livro disponibilizado pelo Google é o Building Secure & Reliable Systems
Mais uma coisa que pode ajudar: Road map DevOps/SRE
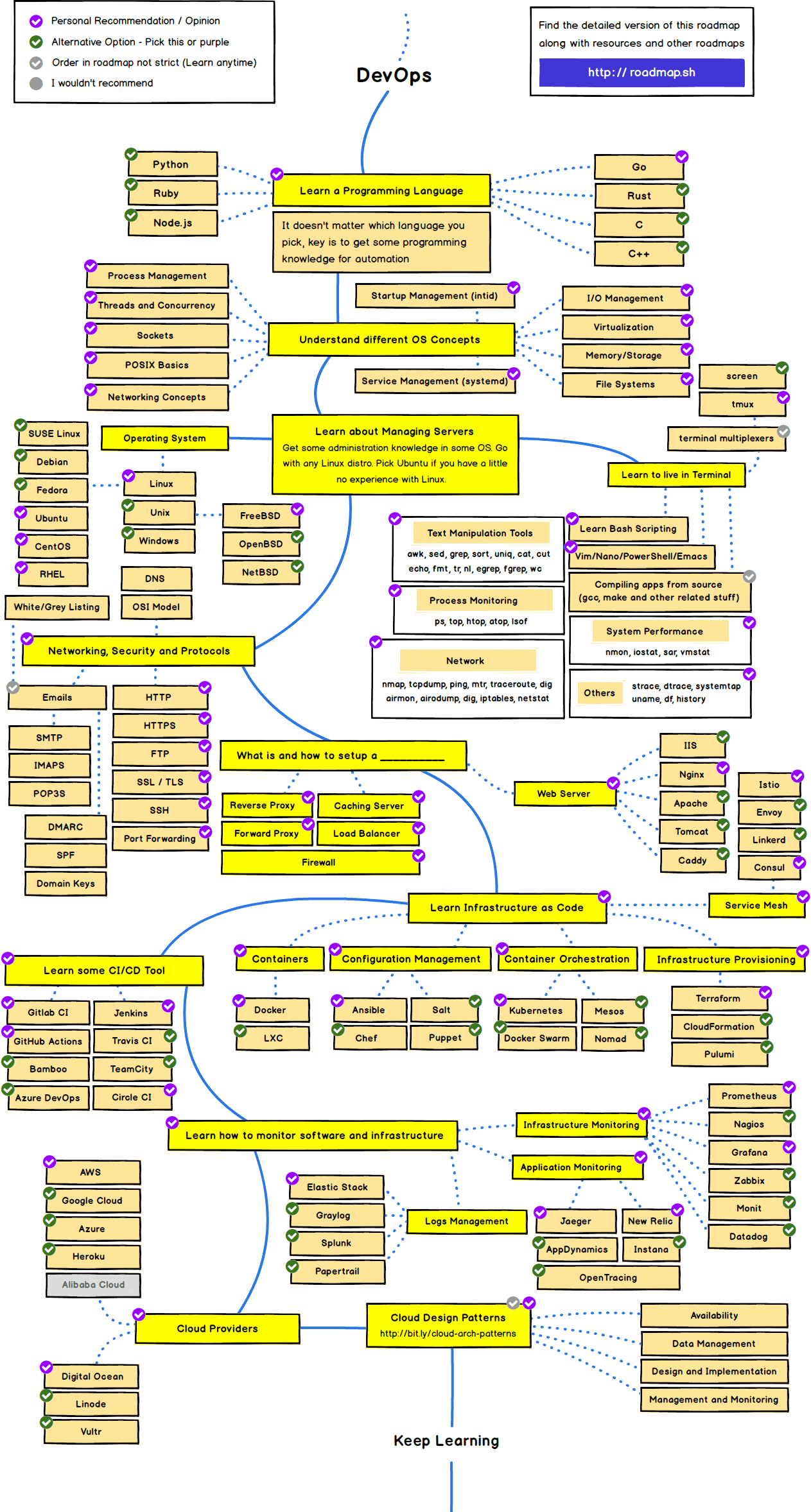
DevOps | SRE - Roadmap
Espero que tenham gostado dos tópicos abordados neste artigo e das dicas de livros.
Deixe seu comentário, siga meu novo perfil no twitter e instagram @sretips, inscreva-se no meu canal do Youtube e fique ligado, pois toda semana teremos videos e novos tópicos que podem ser de seu interesse. Abraço e até a próxima! 😉👍
Referências
- https://www.atlassian.com/br/incident-management/kpis/error-budget
- https://neoteric.eu/blog/what-is-an-error-budget/
- https://blog.estabil.is/o-que-e-sre-site-reliability-engineering/
- https://landing.google.com/sre/books/
- https://learning.oreilly.com/library/view/real-world-sre
- https://learning.oreilly.com/library/view/seeking-sre/9781491978856/part03.html
- https://learning.oreilly.com/library/view/site-reliability-engineering/9781491929117/ch01.html
- https://opensource.com/article/18/10/what-site-reliability-engineer
- https://dwpdigital.blog.gov.uk/category/site-reliability-engineering-sre/
- https://keetmalin.wixsite.com/keetmalin/post/what-is-site-reliability-engineering-sre
- https://cloudposse.com/demo/site-reliability-engineering/
- https://www.xenonstack.com/insights/site-reliability-engineer/
- https://blogs.vmware.com/services-education-insights/files/2018/11/SRE-Paper.pdf
Published on Jun 09, 2020 by Vinicius Moll